(高级)带有 Amazon AWS 的 PyTorch 1.0 分布式训练师
原文: https://pytorch.org/tutorials/beginner/aws_distributed_training_tutorial.html
注意
单击此处的下载完整的示例代码
作者: Nathan Inkawhich
由编辑:滕力
在本教程中,我们将展示如何在两个多 GPU Amazon AWS 节点之间设置,编码和运行 PyTorch 1.0 分布式训练师。 我们将首先描述 AWS 设置,然后是 PyTorch 环境配置,最后是分布式训练师的代码。 希望您会发现将当前的训练代码扩展到分布式应用程序实际上只需很少的代码更改,并且大部分工作都在一次性环境设置中。
Amazon AWS 安装程序
在本教程中,我们将在两个多 GPU 节点之间进行分布式训练。 在本节中,我们将首先介绍如何创建节点,然后介绍如何设置安全组,以便节点之间可以相互通信。
创建节点
在 Amazon AWS 中,有七个创建实例的步骤。 首先,登录并选择 Launch Instance 。
步骤 1:选择一个亚马逊机器映像(AMI)-在这里,我们将选择Deep Learning AMI (Ubuntu) Version 14.0。 如前所述,此实例随附了许多最受欢迎的深度学习框架,并且已预先配置了 CUDA,cuDNN 和 NCCL。 这是本教程的一个很好的起点。
步骤 2:选择实例类型-现在,选择名为p2.8xlarge的 GPU 计算单元。 请注意,每个实例的成本都不同,但是此实例每个节点提供 8 个 NVIDIA Tesla K80 GPU,并为多 GPU 分布式训练提供了良好的体系结构。
步骤 3:配置实例详细信息-此处唯一要更改的设置是将_实例数_增至 2。默认情况下,所有其他配置都可以保留。
步骤 4:添加存储-注意,默认情况下,这些节点没有很多存储(只有 75 GB)。 对于本教程,由于我们仅使用 STL-10 数据集,因此有足够的存储空间。 但是,如果要在较大的数据集(如 ImageNet)上进行训练,则必须添加更多的存储空间以适合数据集和要保存的任何训练后的模型。
步骤 5:添加标签-此处无需执行任何操作,只需继续。
步骤 6:配置安全组-这是配置过程中的关键步骤。 默认情况下,同一安全组中的两个节点将无法在分布式训练设置中进行通信。 在这里,我们要为要加入的两个节点创建一个新的安全组。但是,我们无法在此步骤中完成配置。 现在,只需记住您的新安全组名称(例如 launch-wizard-12),然后继续执行步骤 7。
步骤 7:查看实例启动-在这里,查看实例然后启动它。 默认情况下,这将自动开始初始化两个实例。 您可以从仪表板监视初始化进度。
配置安全组
回想一下,我们在创建实例时无法正确配置安全组。 启动实例后,在 EC2 仪表板中选择_网络&安全>安全组_选项卡。 这将显示您有权访问的安全组的列表。 选择您在步骤 6 中创建的新安全组(即 launch-wizard-12),该安全组将弹出名为 Description,Inbound,Outbound 和 Tags 的标签。 首先,选择_入站_选项卡,然后选择_编辑_,添加一个规则,以允许 launch-wizard-12 安全组中“源”的“所有流量”。 然后选择_出站_选项卡,并执行完全相同的操作。 现在,我们已经有效地允许了 launch-wizard-12 安全组中节点之间所有类型的所有入站和出站流量。
必要信息
在继续之前,我们必须找到并记住两个节点的 IP 地址。 在 EC2 仪表板中找到正在运行的实例。 对于这两种情况,记下 IPv4 公用 IP 和_专用 IP_ 。 在本文档的其余部分,我们将它们称为 node0-publicIP , node0-privateIP , node1-publicIP 和 node1- privateIP 。 公用 IP 是我们将用于 SSH 的地址,而专用 IP 将用于节点间的通信。
环境设定
下一个关键步骤是每个节点的设置。 不幸的是,我们不能同时配置两个节点,因此必须在每个节点上分别完成此过程。 但是,这是一次设置,因此一旦正确配置了节点,就无需为将来的分布式训练项目重新配置。
一旦登录到节点,第一步就是使用 python 3.6 和 numpy 创建一个新的 conda 环境。 创建后,激活环境。
$ conda create -n nightly_pt python=3.6 numpy
$ source activate nightly_pt
接下来,我们将在 conda 环境中安装启用了 Cuda 9.0 的 PyTorch 的每晚构建。
$ pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cu90/torch_nightly.html
我们还必须安装 torchvision,以便可以使用 torchvision 模型和数据集。 目前,我们必须从源代码构建 torchvision,因为默认情况下,pip 安装将在我们刚刚安装的每晚构建的基础上安装旧版本的 PyTorch。
$ cd
$ git clone https://github.com/pytorch/vision.git
$ cd vision
$ python setup.py install
最后,非常重要的步骤是设置 NCCL 套接字的网络接口名称。 这是通过环境变量NCCL_SOCKET_IFNAME设置的。 要获得正确的名称,请在节点上运行ifconfig命令,然后查看与该节点的 privateIP 相对应的接口名称(例如 ens3)。 然后将环境变量设置为
$ export NCCL_SOCKET_IFNAME=ens3
请记住,在两个节点上都执行此操作。 您也可以考虑将 NCCL_SOCKET_IFNAME 设置添加到 .bashrc 中。 一个重要的观察结果是我们没有在节点之间设置共享文件系统。 因此,每个节点都必须具有代码的副本和数据集的副本。 有关在节点之间设置共享网络文件系统的更多信息,请参见。
分布式训练守则
通过运行实例和环境设置,我们现在可以进入训练代码。 这里的大多数代码均来自 PyTorch ImageNet 示例,该示例也支持分布式训练。 该代码为定制训练师提供了一个很好的起点,因为它具有许多样板训练循环,验证循环和准确性跟踪功能。 但是,您会注意到,为简单起见,已删除了参数解析和其他非必要功能。
在此示例中,我们将使用 torchvision.models.resnet18 模型,并将其训练在 torchvision.datasets.STL10 数据集上。 为了适应 STL-10 与 Resnet18 的尺寸不匹配,我们将通过变换将每个图像的大小调整为 224x224。 注意,模型和数据集的选择与分布式训练代码正交,您可以使用所需的任何数据集和模型,并且过程相同。 首先处理导入,然后讨论一些辅助函数。 然后,我们将定义训练和测试功能,这些功能很大程度上取自 ImageNet 示例。 最后,我们将构建处理分布式训练设置的代码的主要部分。 最后,我们将讨论如何实际运行代码。
进口货
这里重要的分布式训练专用导入是 torch.nn.parallel , torch.distributed , torch.utils.data.distributed 和torch.并行处理。 将并行处理启动方法设置为_生成_或 forkserver (仅在 Python 3 中受支持),这一点也很重要,因为默认值为 fork ,这在发生以下情况时可能导致死锁 使用多个工作进程进行数据加载。
import time
import sys
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.distributed as dist
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
from torch.multiprocessing import Pool, Process
辅助功能
我们还必须定义一些辅助函数和类,以使训练更加容易。 AverageMeter类跟踪训练统计信息,例如准确性和迭代计数。 accuracy函数计算并返回模型的 top-k 精度,因此我们可以跟踪学习进度。 两者都是为了训练方便而提供的,但都不是专门针对分布式训练的。
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
火车功能
为了简化主循环,最好将训练纪元步骤分离为一个称为train的函数。 此函数为 train_loader 的一个时期训练输入模型。 此功能中唯一的分布式训练工件是在正向传递之前将数据和标签张量的 non_blocking 属性设置为True。 这允许数据的异步 GPU 副本,意味着传输可以与计算重叠。 此功能还会沿途输出训练统计信息,以便我们可以跟踪整个时期的进度。
在此定义的另一个功能是adjust_learning_rate,它以固定的时间表衰减初始学习率。 这是另一个样板训练器功能,可用于训练准确的模型。
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
# Create non_blocking tensors for distributed training
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec1, prec5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradients in a backward pass
optimizer.zero_grad()
loss.backward()
# Call step of optimizer to update model params
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
def adjust_learning_rate(initial_lr, optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = initial_lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
验证功能
为了跟踪泛化性能并进一步简化主循环,我们还可以将验证步骤提取到一个名为validate的函数中。 此函数在输入验证数据加载器上运行输入模型的完整验证步骤,并在验证集上返回模型的 top-1 准确性。 再次,您会注意到这里唯一的分布式训练功能是在将训练数据和标签传递到模型之前为它们设置non_blocking=True。
def validate(val_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec1, prec5 = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 100 == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1, top5=top5))
print(' * Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(top1=top1, top5=top5))
return top1.avg
输入项
借助辅助功能,现在我们到达了有趣的部分。 在这里,我们将定义运行的输入。 一些输入是标准模型训练输入,例如批次大小和训练时期数,而某些则特定于我们的分布式训练任务。 所需的输入是:
- batch_size -分布式训练组中每个进程的_的批处理大小。 整个分布式模型的总批次大小为 batch_size * world_size_
- worker -每个进程中与数据加载器一起使用的工作进程数
- num_epochs -要训练的时期总数
- starting_lr -训练的开始学习率
- world_size -分布式训练环境中的进程数
- dist_backend -用于分布式训练通信(即 NCCL,Glo,MPI 等)的后端。 在本教程中,由于我们使用了多个多 GPU 节点,因此建议使用 NCCL。
- dist_url -用于指定进程组的初始化方法的 URL。 它可能包含 rank0 进程的 IP 地址和端口,或者是共享文件系统上不存在的文件。 在这里,由于我们没有共享文件系统,因此它将合并 node0-privateIP 和 node0 上要使用的端口。
print("Collect Inputs...")
# Batch Size for training and testing
batch_size = 32
# Number of additional worker processes for dataloading
workers = 2
# Number of epochs to train for
num_epochs = 2
# Starting Learning Rate
starting_lr = 0.1
# Number of distributed processes
world_size = 4
# Distributed backend type
dist_backend = 'nccl'
# Url used to setup distributed training
dist_url = "tcp://172.31.22.234:23456"
初始化流程组
在 PyTorch 中,分布式训练最重要的部分之一就是正确设置过程组,这是初始化torch.distributed包时首先执行的步骤。 为此,我们将使用torch.distributed.init_process_group函数,该函数需要多个输入。 首先,后端_输入指定要使用的后端(即 NCCL,Gloo,MPI 等)。 _init_method 输入,该 URL 是包含 rank0 计算机的地址和端口的 url,或者是共享文件系统上不存在的文件的路径。 注意,要使用文件 init_method,所有计算机都必须有权访问该文件,对于 url 方法而言,所有计算机都必须能够在网络上进行通信,因此请确保配置所有防火墙和网络设置以使其适应。 init_process_group 函数还采用_等级_和 world_size 自变量,它们分别指定运行时此进程的等级和集合中的进程数。 init_method 输入也可以是“ env://”。 在这种情况下,将分别从以下两个环境变量中读取 rank0 机器的地址和端口:MASTER_ADDR,MASTER_PORT。 如果在 init_process_group 函数中未指定_等级_和 world_size 参数,则也可以分别从以下两个环境变量中读取它们:RANK,WORLD_SIZE。
另一个重要步骤(尤其是当每个节点具有多个 GPU 时)是设置此过程的 local_rank 。 例如,如果您有两个节点,每个节点有 8 个 GPU,并且您希望对其全部进行训练,则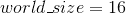 ,每个节点将具有本地等级 0-7 的进程。 此 local_rank 用于设置进程的设备(即使用哪个 GPU),后来在创建分布式数据并行模型时用于设置设备。 还建议在此假设环境中使用 NCCL 后端,因为对于多 GPU 节点,首选 NCCL。
,每个节点将具有本地等级 0-7 的进程。 此 local_rank 用于设置进程的设备(即使用哪个 GPU),后来在创建分布式数据并行模型时用于设置设备。 还建议在此假设环境中使用 NCCL 后端,因为对于多 GPU 节点,首选 NCCL。
print("Initialize Process Group...")
# Initialize Process Group
# v1 - init with url
dist.init_process_group(backend=dist_backend, init_method=dist_url, rank=int(sys.argv[1]), world_size=world_size)
# v2 - init with file
# dist.init_process_group(backend="nccl", init_method="file:///home/ubuntu/pt-distributed-tutorial/trainfile", rank=int(sys.argv[1]), world_size=world_size)
# v3 - init with environment variables
# dist.init_process_group(backend="nccl", init_method="env://", rank=int(sys.argv[1]), world_size=world_size)
# Establish Local Rank and set device on this node
local_rank = int(sys.argv[2])
dp_device_ids = [local_rank]
torch.cuda.set_device(local_rank)
初始化模型
下一步是初始化要训练的模型。 在这里,我们将使用torchvision.models中的 resnet18 模型,但可以使用任何模型。 首先,我们初始化模型并将其放置在 GPU 内存中。 接下来,我们制作模型DistributedDataParallel,该模型处理与模型之间的数据分配,这对于分布式训练至关重要。 DistributedDataParallel模块还可以处理世界范围内的梯度平均,因此我们不必在训练步骤中明确地对梯度进行平均。
重要的是要注意,这是一个阻塞函数,这意味着程序执行将在此函数等待,直到 world_size 进程加入进程组为止。 另外,请注意,我们将设备 ID 列表作为参数传递,其中包含我们正在使用的本地排名(即 GPU)。 最后,我们指定损失函数和优化器来训练模型。
print("Initialize Model...")
# Construct Model
model = models.resnet18(pretrained=False).cuda()
# Make model DistributedDataParallel
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=dp_device_ids, output_device=local_rank)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), starting_lr, momentum=0.9, weight_decay=1e-4)
初始化数据加载器
准备训练的最后一步是指定要使用的数据集。 这里,我们使用 torchvision.datasets.STL10 中的 STL-10 数据集。 STL10 数据集是 96x96px 彩色图像的 10 类数据集。 为了与我们的模型一起使用,我们在转换中将图像的大小调整为 224x224px。 本节中的一项分布式训练特定项目是将DistributedSampler用于训练集,该训练集旨在与DistributedDataParallel模型结合使用。 该对象处理整个分布式环境中数据集的分区,因此并非所有模型都在同一数据子集上进行训练,这会适得其反。 最后,我们创建DataLoader,负责将数据馈送到流程中。
如果节点不存在,STL-10 数据集将自动在节点上下载。 如果您希望使用自己的数据集,则应下载数据,编写自己的数据集处理程序,并在此处为数据集构造一个数据加载器。
print("Initialize Dataloaders...")
# Define the transform for the data. Notice, we must resize to 224x224 with this dataset and model.
transform = transforms.Compose(
[transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# Initialize Datasets. STL10 will automatically download if not present
trainset = datasets.STL10(root='./data', split='train', download=True, transform=transform)
valset = datasets.STL10(root='./data', split='test', download=True, transform=transform)
# Create DistributedSampler to handle distributing the dataset across nodes when training
# This can only be called after torch.distributed.init_process_group is called
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
# Create the Dataloaders to feed data to the training and validation steps
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=(train_sampler is None), num_workers=workers, pin_memory=False, sampler=train_sampler)
val_loader = torch.utils.data.DataLoader(valset, batch_size=batch_size, shuffle=False, num_workers=workers, pin_memory=False)
训练循环
最后一步是定义训练循环。 我们已经完成了设置分布式训练的大部分工作,因此这不是特定于分布式训练的。 唯一的细节是在DistributedSampler中设置当前纪元计数,因为采样器会根据纪元确定性地随机整理进入每个进程的数据。 更新采样器后,循环将运行一个完整的训练时期,运行一个完整的验证步骤,然后将当前模型的性能与迄今为止性能最佳的模型进行比较。 训练完 num_epochs 之后,循环退出,并且教程已完成。 注意,由于这是一项练习,因此我们没有保存模型,但是可能希望跟踪性能最佳的模型,然后在训练结束时保存模型(请参见,在此处)。
best_prec1 = 0
for epoch in range(num_epochs):
# Set epoch count for DistributedSampler
train_sampler.set_epoch(epoch)
# Adjust learning rate according to schedule
adjust_learning_rate(starting_lr, optimizer, epoch)
# train for one epoch
print("\nBegin Training Epoch {}".format(epoch+1))
train(train_loader, model, criterion, optimizer, epoch)
# evaluate on validation set
print("Begin Validation @ Epoch {}".format(epoch+1))
prec1 = validate(val_loader, model, criterion)
# remember best prec@1 and save checkpoint if desired
# is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
print("Epoch Summary: ")
print("\tEpoch Accuracy: {}".format(prec1))
print("\tBest Accuracy: {}".format(best_prec1))
运行代码
与大多数其他 PyTorch 教程不同,此代码可能无法直接在笔记本中运行。 要运行,请下载此文件的.py 版本(或使用此进行转换),然后将副本上载到两个节点。 精明的读者会注意到,我们对 node0-privateIP 和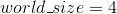 进行了硬编码,但输入了_等级_和 local_rank 输入为 arg [1]和 arg [ 2]命令行参数。 上传后,在每个节点中打开两个 ssh 终端。
进行了硬编码,但输入了_等级_和 local_rank 输入为 arg [1]和 arg [ 2]命令行参数。 上传后,在每个节点中打开两个 ssh 终端。
- 在 node0 的第一个终端上,运行
$ python main.py 0 0 - 在 node0 的第二个终端上运行
$ python main.py 1 1 - 在节点 1 的第一个终端上,运行
$ python main.py 2 0 - 在 node1 的第二个终端上运行
$ python main.py 3 1
在打印“ Initialize Model…”之后,程序将启动并等待所有四个进程加入该进程组。 请注意,第一个参数没有重复,因为这是该过程的唯一全局等级。 重复第二个参数,因为这是在节点上运行的进程的本地等级。 如果在每个节点上运行nvidia-smi,则将在每个节点上看到两个进程,一个在 GPU0 上运行,一个在 GPU1 上运行。
我们现在已经完成了分布式训练示例! 希望您能看到如何使用本教程来帮助您在自己的数据集上训练自己的模型,即使您没有使用完全相同的分布式环境。 如果您使用的是 AWS,请不要忘记按一下来关闭您的节点,否则在月底可能会发现一张大笔的账单。
接下来要去哪里
- 查看启动器实用程序,以其他方式开始运行
- 查看 torch.multiprocessing.spawn 实用程序,了解启动多个分布式进程的另一种简便方法。 PyTorch ImageNet 示例已实现并可以演示如何使用它。
- 如果可能,请设置一个 NFS,以便您仅需要数据集的一个副本
脚本的总运行时间:(0 分钟 0.000 秒)
Download Python source code: aws_distributed_training_tutorial.py Download Jupyter notebook: aws_distributed_training_tutorial.ipynb
由狮身人面像画廊生成的画廊
