经常问的问题
我的模型报告“ CUDA 运行时错误(2):内存不足”
如错误消息所暗示,您的 GPU 内存已用完。 由于我们经常在 PyTorch 中处理大量数据,因此小错误可能会迅速导致您的程序用尽所有 GPU; 幸运的是,这些情况下的修复程序通常很简单。 以下是一些常见的检查事项:
不要在整个训练循环中累积历史记录。 默认情况下,涉及需要渐变的变量的计算将保留历史记录。 这意味着您应避免在计算中使用此类变量,这些变量将不受训练循环的影响,例如在跟踪统计信息时。 相反,您应该分离变量或访问其基础数据。
有时,可微变量发生时可能不是很明显。 考虑以下训练循环(从源删节):
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
loss.backward()
optimizer.step()
total_loss += loss
在这里,total_loss会在您的训练循环中累积历史记录,因为loss是具有自动分级历史记录的可微变量。 您可以改写 <cite>total_loss + = float(loss)</cite>来解决此问题。
此问题的其他实例: 1 。
不要使用不需要的张量和变量。 如果将 Tensor 或 Variable 分配给本地,Python 将不会取消分配,直到本地超出范围。 您可以使用del x释放此参考。 同样,如果将 Tensor 或 Variable 分配给对象的成员变量,则在对象超出范围之前它不会释放。 如果不使用不需要的临时存储,则将获得最佳的内存使用率。
当地人的范围可能会超出您的预期。 例如:
for i in range(5):
intermediate = f(input[i])
result += g(intermediate)
output = h(result)
return output
这里,即使h正在执行,intermediate仍保持活动状态,因为它的作用域超出了循环的结尾。 要提早释放它,使用完后应del intermediate。
不要对太大的序列运行 RNN。 通过 RNN 反向传播所需的内存量与 RNN 输入的长度成线性比例; 因此,如果您尝试向 RNN 输入过长的序列,则会耗尽内存。
这种现象的技术术语是到时间的反向传播,关于如何实现截断 BPTT 的参考很多,包括字语言模型示例; 截断由本论坛帖子中所述的repackage功能处理。
请勿使用太大的线性图层。 线性层nn.Linear(m, n)使用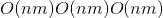 内存:也就是说,权重的内存要求与要素数量成正比关系。 以这种方式穿透内存非常容易(请记住,您至少需要权重大小的两倍,因为您还需要存储渐变。)
内存:也就是说,权重的内存要求与要素数量成正比关系。 以这种方式穿透内存非常容易(请记住,您至少需要权重大小的两倍,因为您还需要存储渐变。)
我的 GPU 内存未正确释放
PyTorch 使用缓存内存分配器来加速内存分配。 因此,nvidia-smi中显示的值通常不能反映真实的内存使用情况。 有关 GPU 内存管理的更多详细信息,请参见内存管理。
如果即使在退出 Python 后仍没有释放 GPU 内存,则很可能某些 Python 子进程仍然存在。 您可以通过ps -elf | grep python找到它们,然后使用kill -9 [pid]手动将其杀死。
我的数据加载器工作人员返回相同的随机数
您可能会使用其他库在数据集中生成随机数。 例如,当通过fork启动工作程序子流程时,NumPy 的 RNG 被复制。 请参阅 torch.utils.data.DataLoader 的文档,以了解如何通过worker_init_fn选项在工人中正确设置随机种子。
我的经常性网络无法使用数据并行性
在 Module 与 DataParallel 或 data_parallel() 中使用pack sequence -> recurrent network -> unpack sequence模式是很微妙的。 每个设备上每个forward()的输入仅是整个输入的一部分。 由于默认情况下,拆包操作 torch.nn.utils.rnn.pad_packed_sequence() 仅填充其看到的最长输入,即该特定设备上的最长输入,因此,将结果汇总在一起时会发生大小不匹配的情况。 因此,您可以改而利用 pad_packed_sequence() 的total_length自变量来确保forward()调用相同长度的返回序列。 例如,您可以编写:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class MyModule(nn.Module):
# ... __init__, other methods, etc.
# padded_input is of shape [B x T x *] (batch_first mode) and contains
# the sequences sorted by lengths
# B is the batch size
# T is max sequence length
def forward(self, padded_input, input_lengths):
total_length = padded_input.size(1) # get the max sequence length
packed_input = pack_padded_sequence(padded_input, input_lengths,
batch_first=True)
packed_output, _ = self.my_lstm(packed_input)
output, _ = pad_packed_sequence(packed_output, batch_first=True,
total_length=total_length)
return output
m = MyModule().cuda()
dp_m = nn.DataParallel(m)
此外,当批处理尺寸为1(即batch_first=False)且数据平行时,需要格外小心。 在这种情况下,pack_padded_sequence padding_input的第一个参数的形状将为[T x B x *],并且应沿昏暗1分散,而第二个参数input_lengths的形状将为[B],并且应沿昏暗[[Gate] 0。 将需要额外的代码来操纵张量形状。
